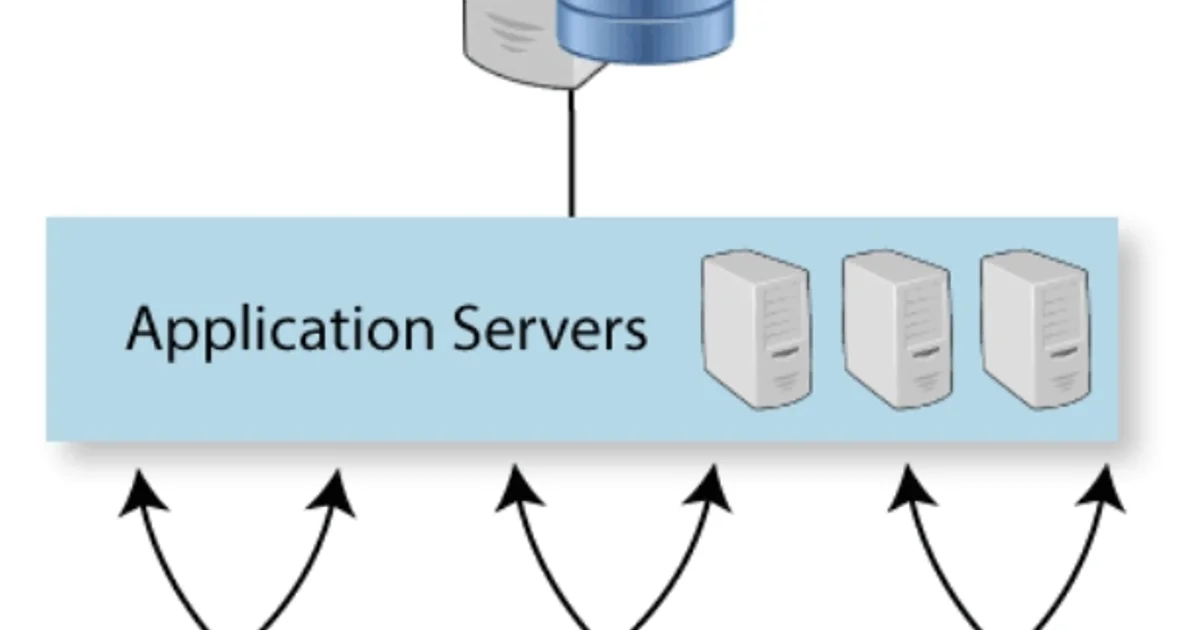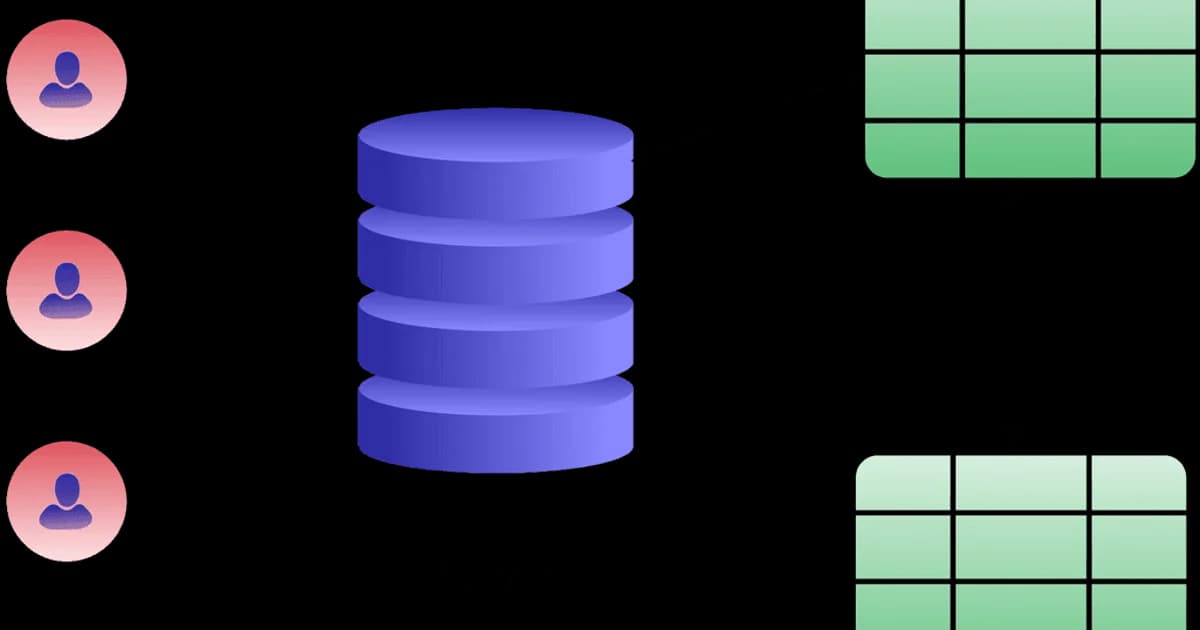
Databases
Connection Pooling: Why PgBouncer Exists and How It Works
A complete guide to PostgreSQL connection pooling with PgBouncer. Covers the process-per-connection model, pooling modes (session, transaction, statement), configuration, Kubernetes deployment patterns, and alternatives.
10 min read·