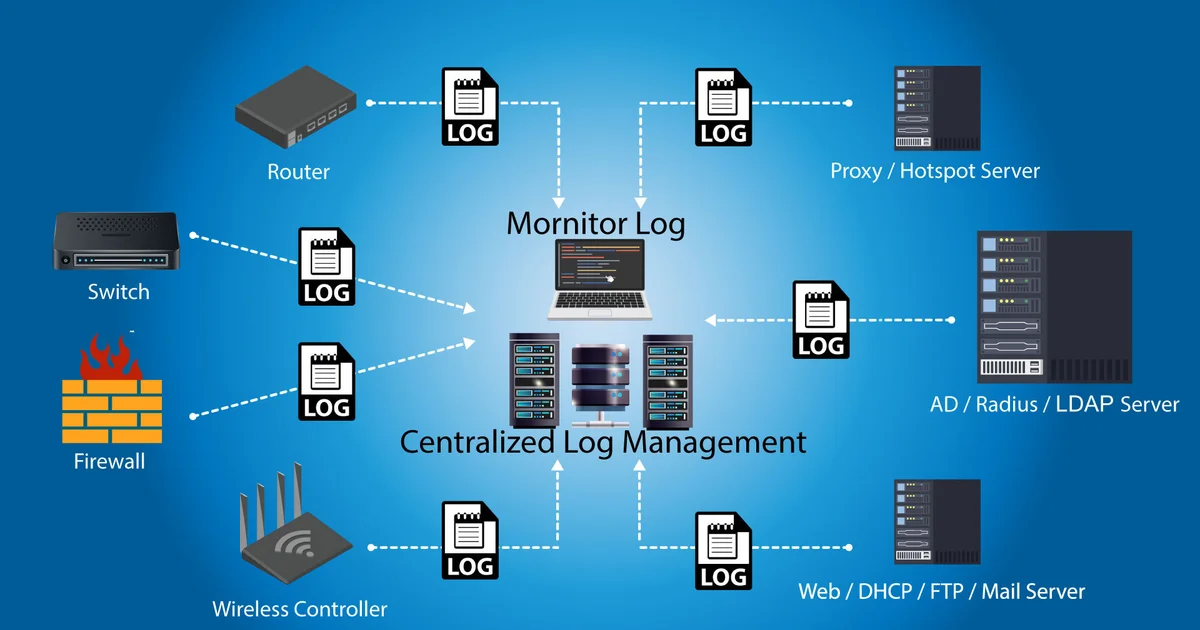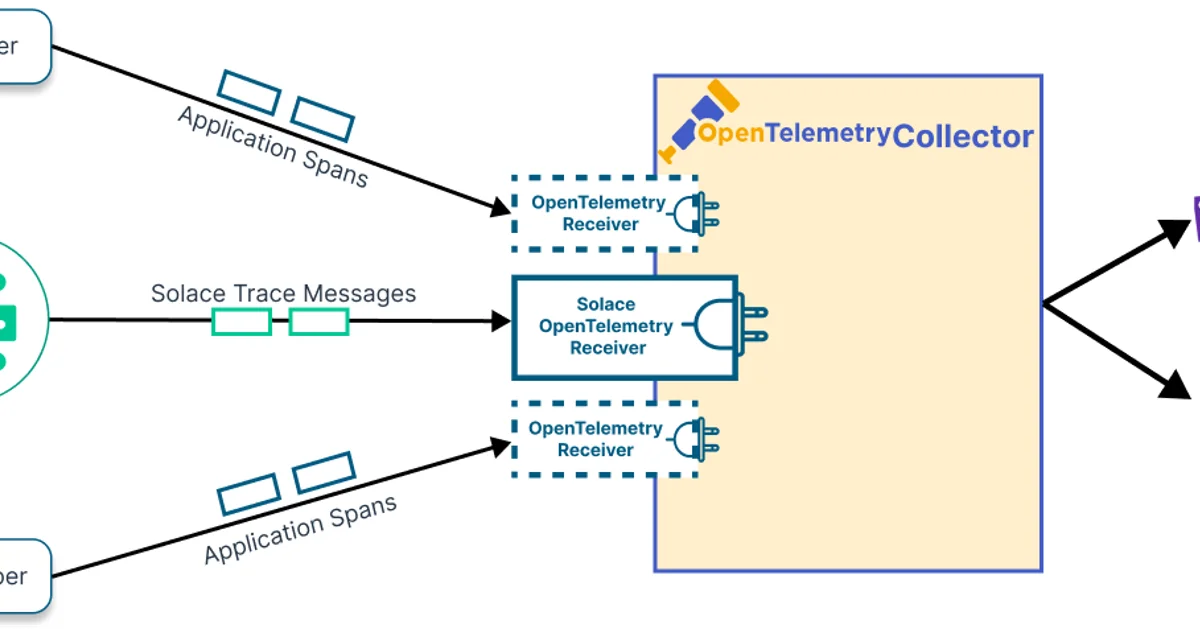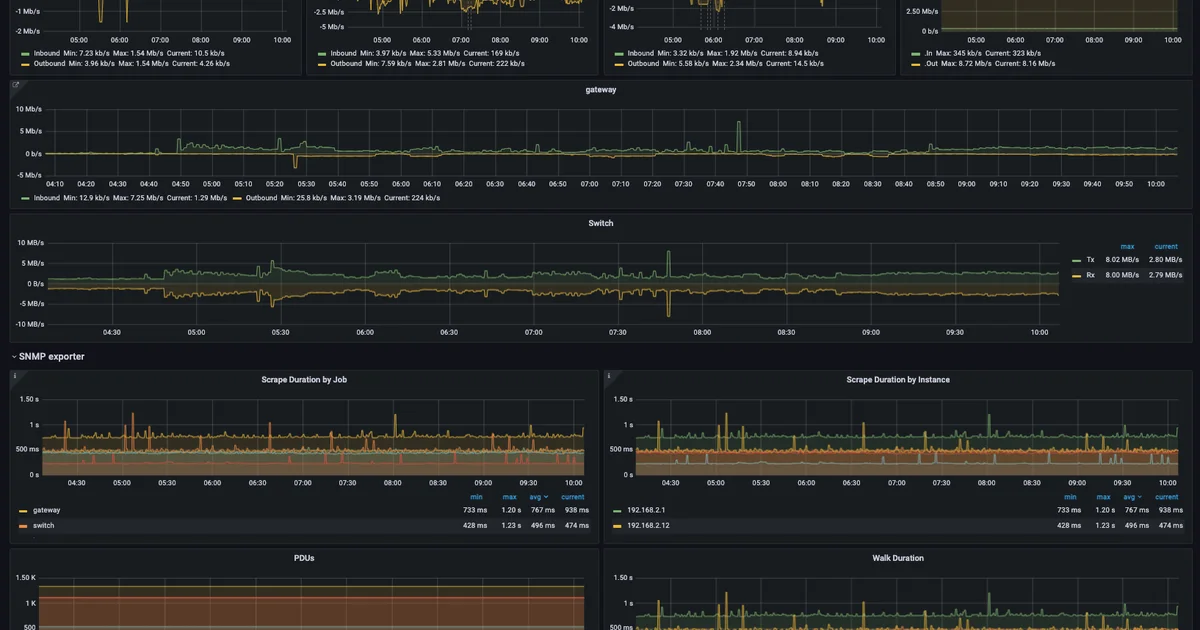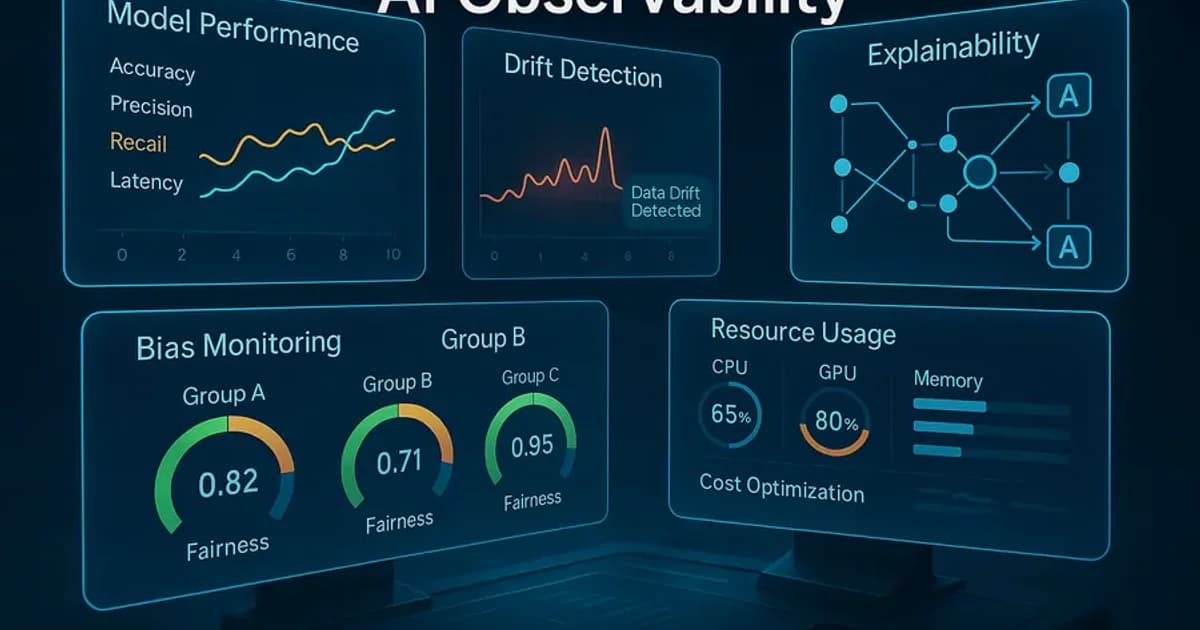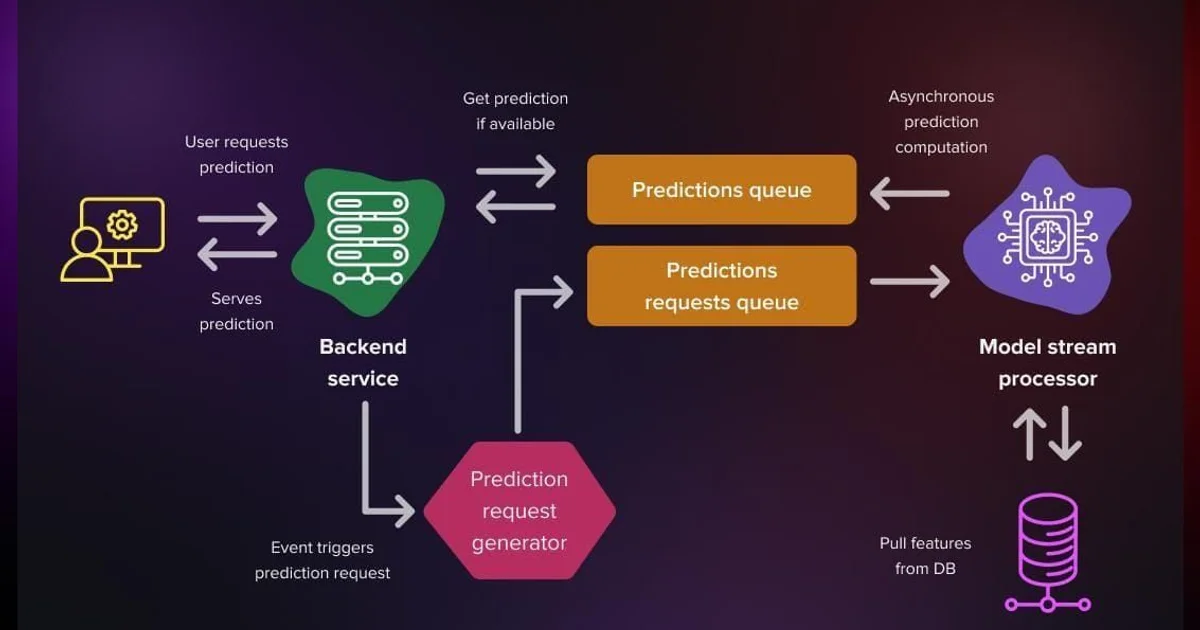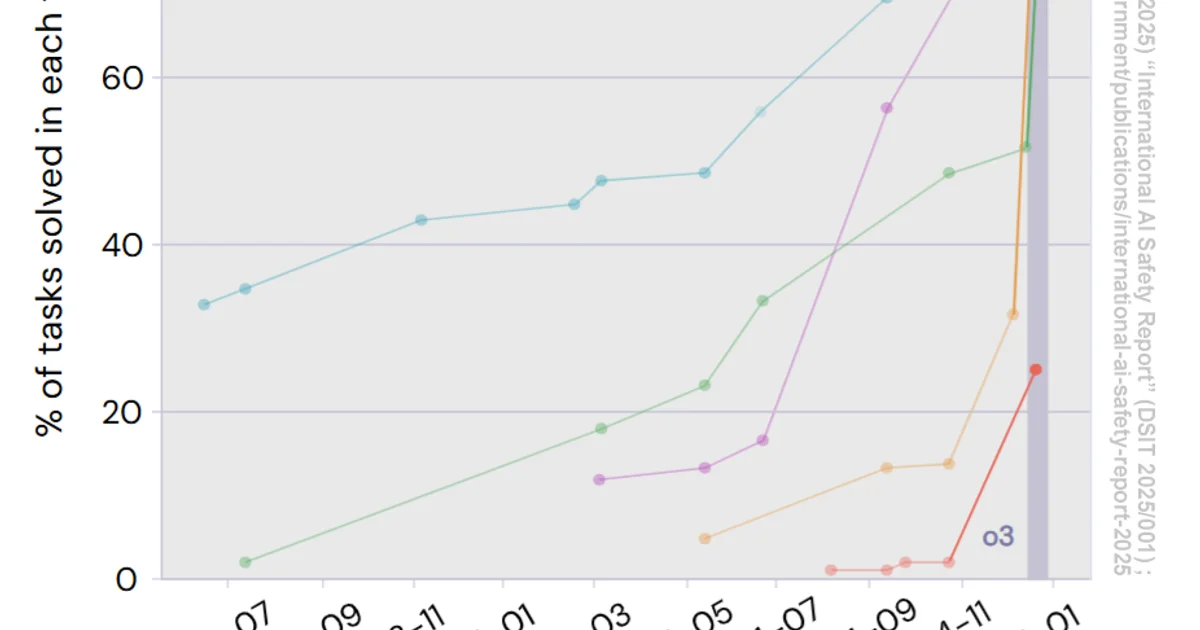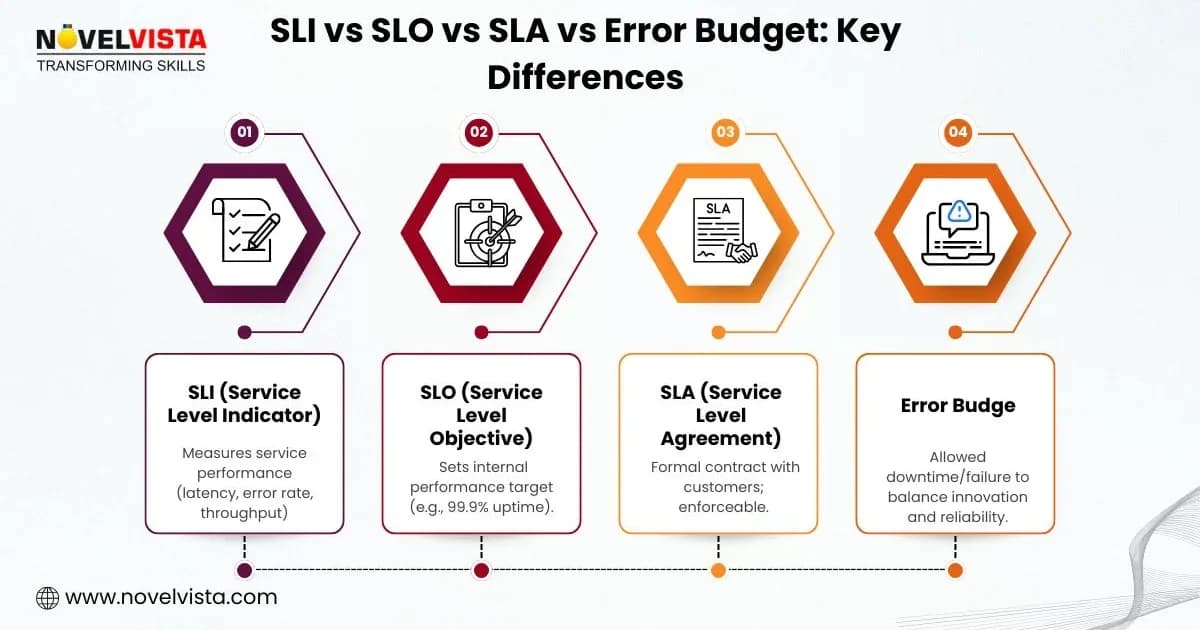
Observability
SLOs, SLAs, and Error Budgets: Running Reliable Services
SLOs, SLAs, and error budgets turn reliability into a measurable resource. Learn how to choose SLIs, set realistic targets, calculate error budgets, and implement burn rate alerts with Prometheus.
11 min read·